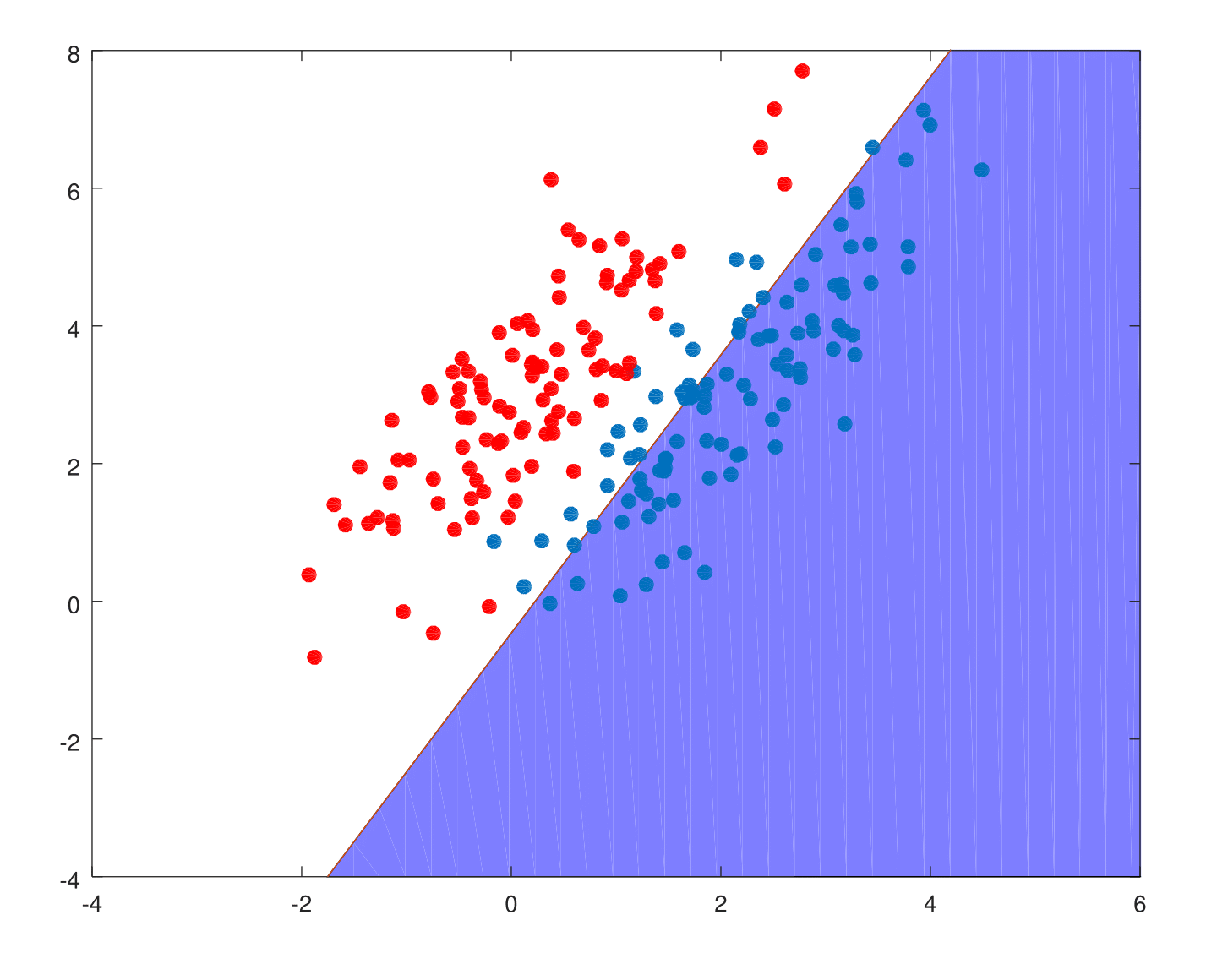
We first create training data for \(Y=1\), denoted by \(X_{pos}\) and \(Y=-1\), denoted by \(X_{neg}\).
mu_pos = [2,3];
mu_neg = [0,3];
sigma = [1,1.5;1.5,3];
X_pos = mvnrnd(mu_pos,sigma,100);
X_neg = mvnrnd(mu_neg,sigma,100);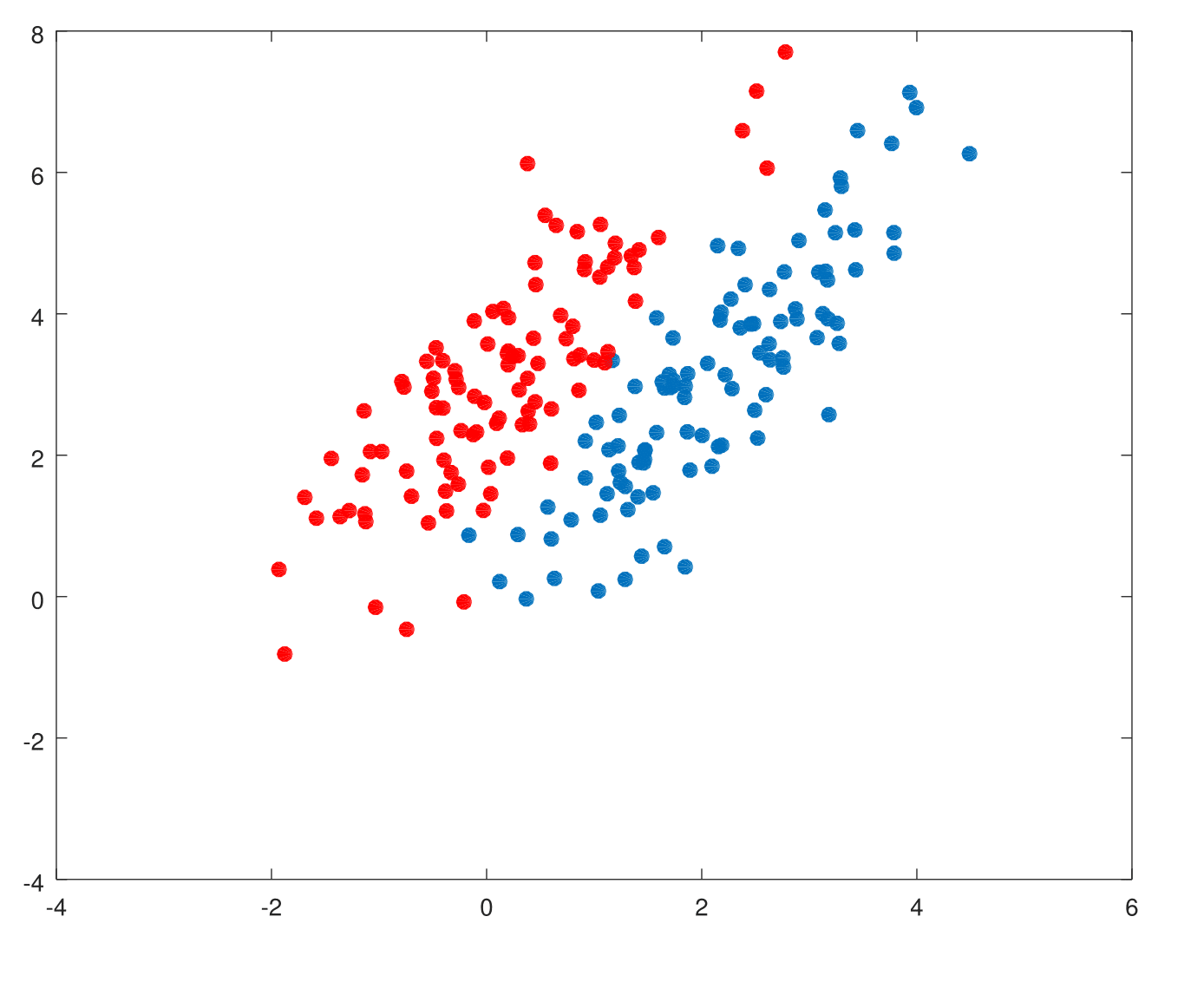
Let’s evaluate two simple but powerful prediction methods: the linear model fit by least squares and the \(k\)-nearest-neighbor prediction rule on a simple regression problem. We will see how the linear model makes huge assumptions about structure and yields stable but possibly inaccurate predictions. The method of \(k\)-nearest neighbors, however, makes very mild structural assumptions: its predictions are often accurate but can be unstable.
Consider the two possible scenarios:
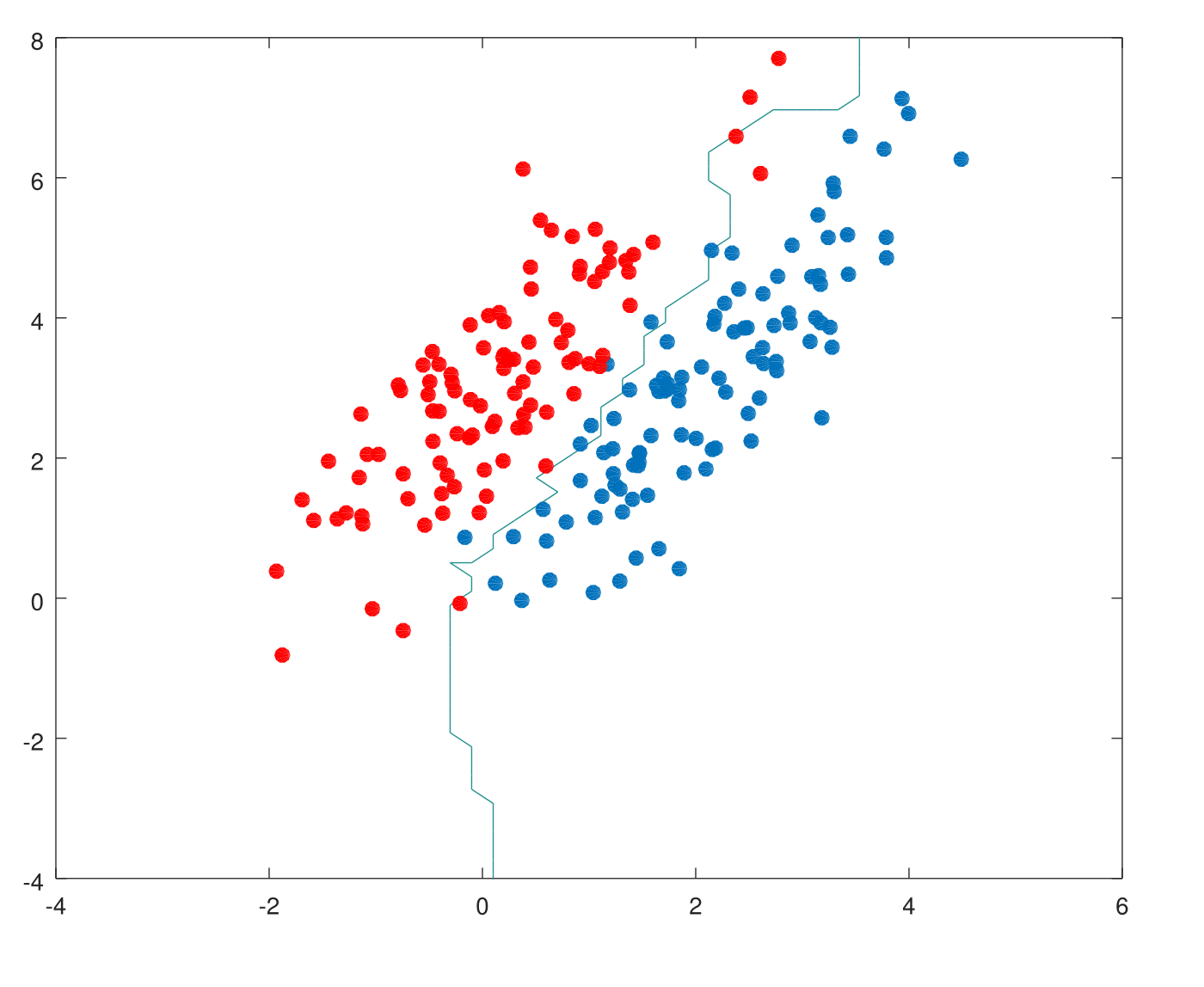
Scenario 1: The training data in each class were generated from bivariate Gaussian distribution with uncorrelated components and different means.
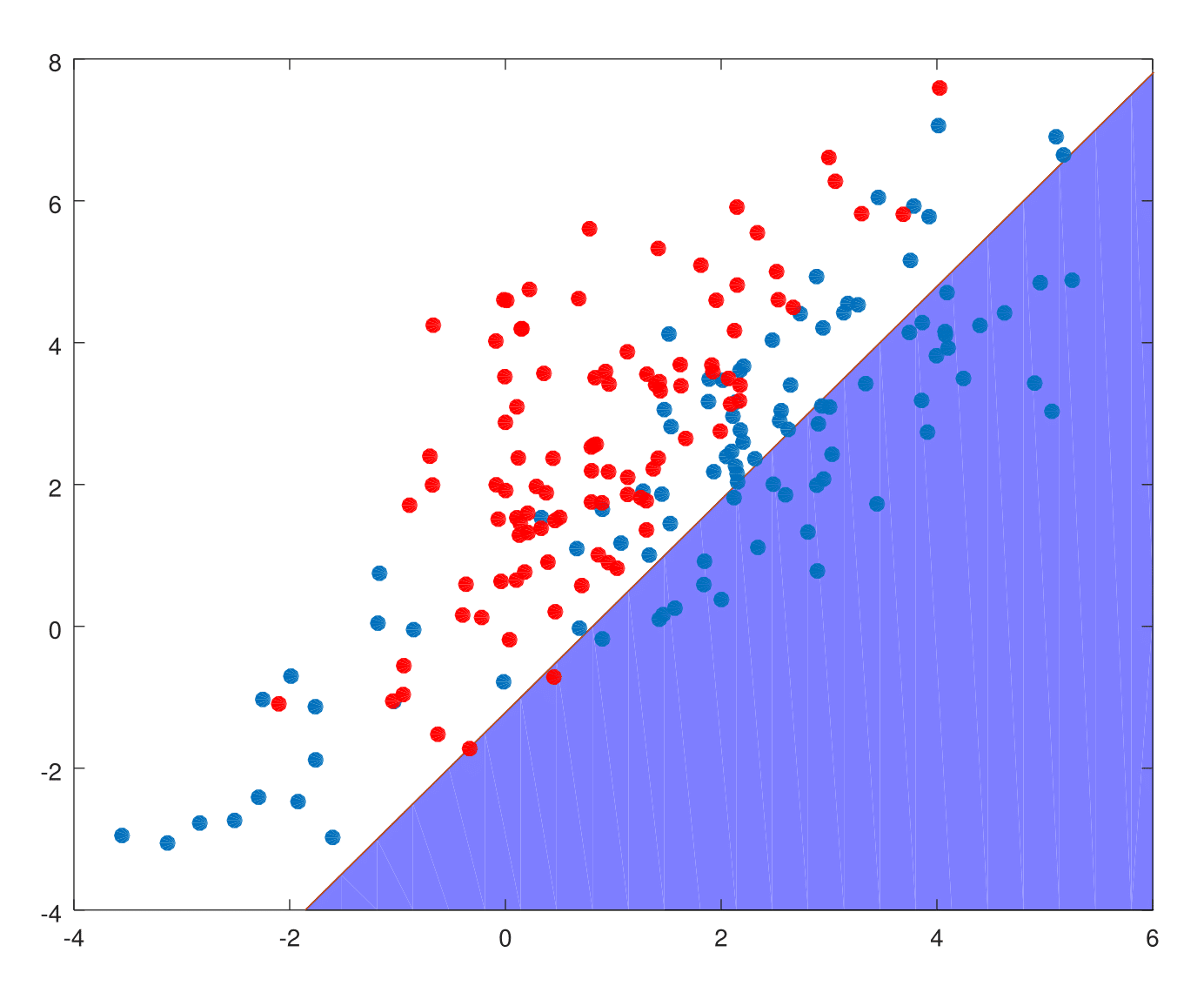
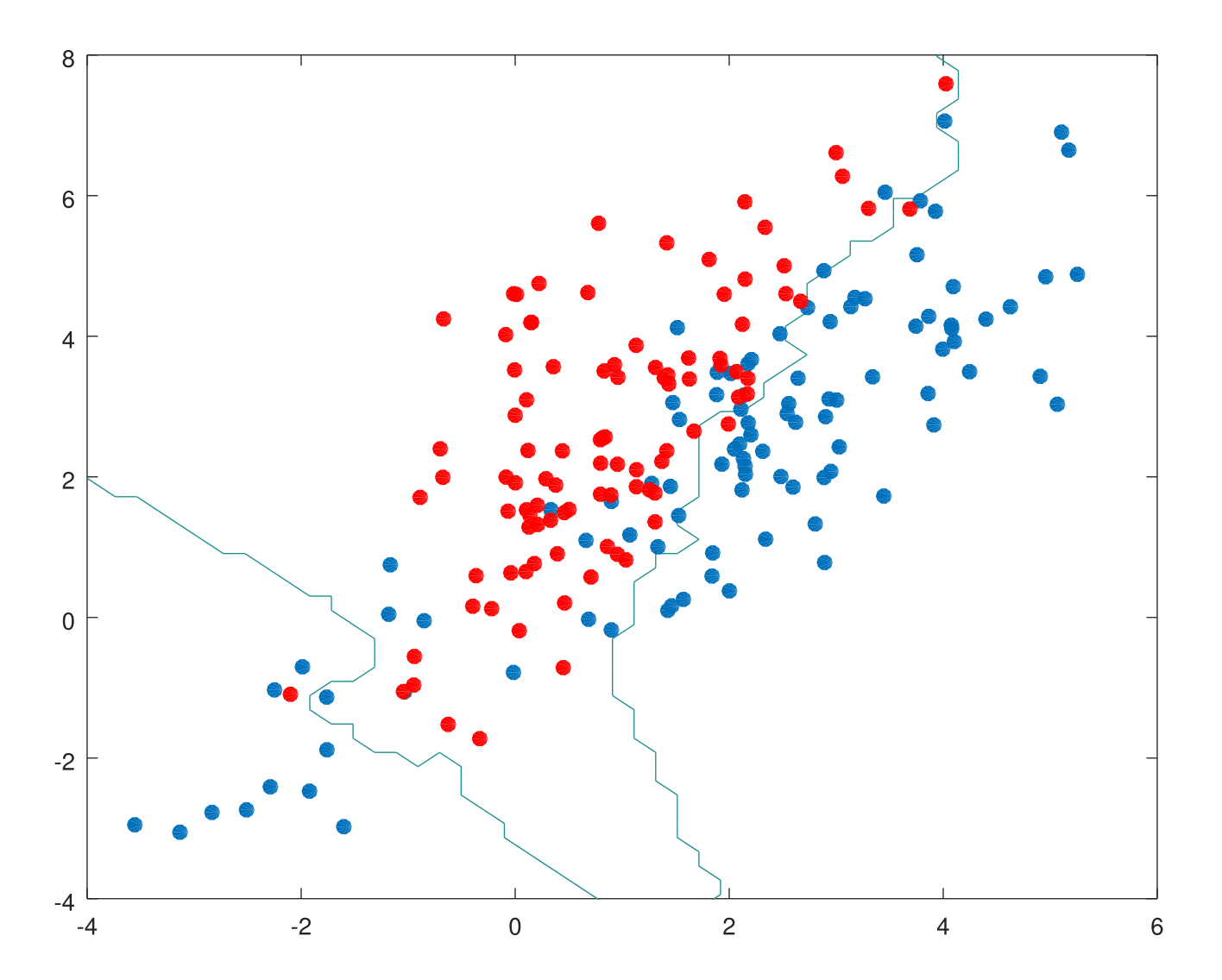
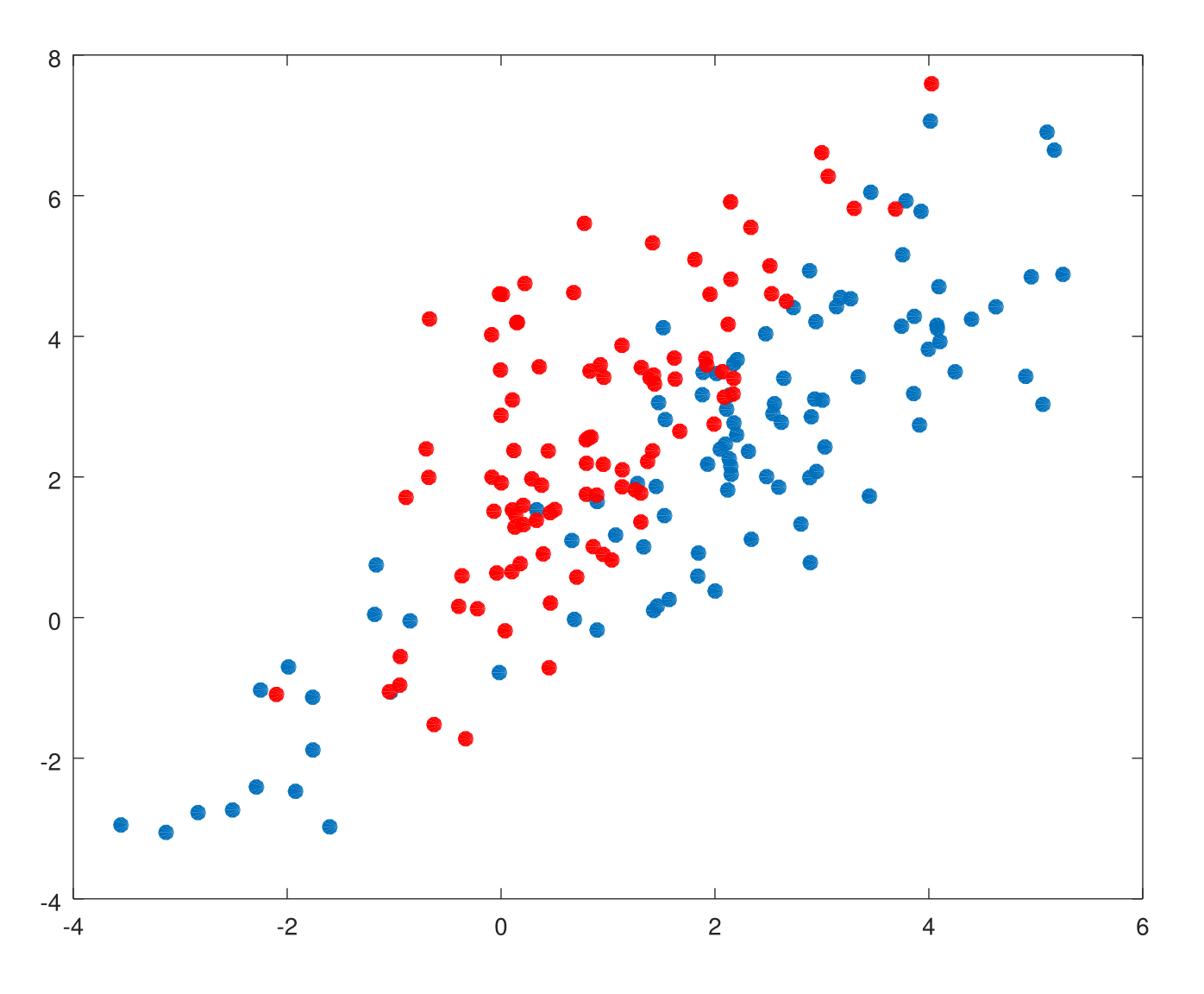
Scenario 2: The training data in each class came from a mixture of 10 low-variance Gaussian distributions, with individual means themselves distributed as Gaussian.
We first create training data for \(Y=1\), denoted by \(X_{pos}\) and \(Y=-1\), denoted by \(X_{neg}\).
mu_pos = [2,3];
mu_neg = [0,3];
sigma = [1,1.5;1.5,3];
X_pos = mvnrnd(mu_pos,sigma,100);
X_neg = mvnrnd(mu_neg,sigma,100);
This is how least squares performs on both scenarios.
X = [zeros(200,1)+1 [X_neg; X_pos]];
Y = [zeros(100,1)-1;zeros(100,1)+1];
param = inv(transpose(X)*X)*transpose(X)*Y;
This is how nearest neighbors performs for k=10.
We can actually develop some theory that provides a framework for developing models such as those discussed informally so far. As discussed in another post, for squared error loss function, the regression function is \[f(x)=E(Y|X=x)\]
The nearest-neighbor methods attempt to directly implement this recipe using the training data. At each point \(x\), we might ask for the average of all those \(y_is\) with input \(x_i=x\). Since there is typically at most one observation at any point \(x\), we settle for \[\hat{f}(x)=Ave(y_i|x_i \in N_k(x))\] where \(“Ave”\) denotes average, and \(N_k(x)\) is the neighborhood containing the \(k\) points in \(T\) closest to \(x\). Two approximations are happening here:
How does linear regression fit into this framework? The simplest explanation is that one assumes that the regression function \(f(x)\) is approximately linear in its arguments: \[f(x) \approx x^T\beta\] This is a model-based approach- we specify a model for the regression function. Plugging this linear model for \(f(x)\) into \(EPE\) and differentiating we can solve for \(\beta\) theoretically: \[\beta = (E(XX^T))^{-1} E(XY)\] Note we have not conditioned on \(X\); rather we have used our knowledge of the functional relationship to pool over values of \(X\). The least squares solution amounts to replacing the expectation b averages overs the training data.
So both \(k\)-nearest neighbors and least squares end up approximating conditional expectations by averages. But they differ dramatically in terms of model assumptions: